
Практика По Администрированию Oracle 11g I 2017 (Блок 3 Лабораторные 10-13)
Практика По Администрированию Oracle 11g I 2017 (Блок 3 Лабораторные 10-13)
Вам также может понравиться
- Hibernate Recipes, 2nd EditionДокумент271 страницаHibernate Recipes, 2nd EditionAna ButurajacОценок пока нет
- Практика освоения ABAP CDS для непрограммистов. Часть 1Документ88 страницПрактика освоения ABAP CDS для непрограммистов. Часть 1Rasul11Оценок пока нет
- 10 Лекция - Хранимые процедуры и триггерыДокумент17 страниц10 Лекция - Хранимые процедуры и триггерыmokawar960Оценок пока нет
- НАСТРОЙКА БД Oracle Primavera P6Документ14 страницНАСТРОЙКА БД Oracle Primavera P6Андрей МакаренкоОценок пока нет
- АИС AMOSДокумент10 страницАИС AMOSНатОценок пока нет
- НИРДокумент7 страницНИРsuhorukovdmitryОценок пока нет
- ROWERCENTER INTEGRATSIYA DANNYH DLYA RAZRABOTCHIKOV UROVEN 2 - v25092018Документ6 страницROWERCENTER INTEGRATSIYA DANNYH DLYA RAZRABOTCHIKOV UROVEN 2 - v25092018ПетрОценок пока нет
- Контрольные вопросы по 1С.Документ3 страницыКонтрольные вопросы по 1С.nwytgnetОценок пока нет
- SQL LektsiiRusДокумент48 страницSQL LektsiiRusbegimayОценок пока нет
- Abap Cds. Определение Ракурсов и Профилей в Репозитарии. (s4d430)Документ17 страницAbap Cds. Определение Ракурсов и Профилей в Репозитарии. (s4d430)Сергей З.Оценок пока нет
- МУ по ЛР, БСБДДокумент42 страницыМУ по ЛР, БСБДAlexОценок пока нет
- ПВНСЗД ПЗ № 1Документ39 страницПВНСЗД ПЗ № 1vladyslav.ulanОценок пока нет
- Обслуживание БДДокумент16 страницОбслуживание БДIt's somethingОценок пока нет
- Change NotificationДокумент31 страницаChange NotificationOlga ShОценок пока нет
- PCS P02 83Документ4 страницыPCS P02 83gosiw74599Оценок пока нет
- Администрирование ViPNet (W L) - Практикум 8.12 - 8.13. СОХРАНЕНИЕ НАСТРОЕК. РАСПИСАНИЕДокумент3 страницыАдминистрирование ViPNet (W L) - Практикум 8.12 - 8.13. СОХРАНЕНИЕ НАСТРОЕК. РАСПИСАНИЕKv142 KvОценок пока нет
- ! - Руководство По MySQL - metanit - 81стр - 2018Документ77 страниц! - Руководство По MySQL - metanit - 81стр - 2018OlyaОценок пока нет
- Администрирование базы данныхДокумент28 страницАдминистрирование базы данныхНиколай ДиканскийОценок пока нет
- Документ Microsoft WordДокумент2 страницыДокумент Microsoft WordSergey KomlevОценок пока нет
- Ramus Laba IDEF DFDДокумент18 страницRamus Laba IDEF DFDArseniy RedzhepovОценок пока нет
- Практическая Работа с Механизмами РасширениямиДокумент6 страницПрактическая Работа с Механизмами РасширениямиHelenОценок пока нет
- SQL Advanced - Лекция 2Документ28 страницSQL Advanced - Лекция 2Кристина КабановаОценок пока нет
- IG Content Server 640Документ16 страницIG Content Server 640borinsky1Оценок пока нет
- Доклад по Microsoft AzureДокумент5 страницДоклад по Microsoft AzureVictorОценок пока нет
- 12.2.1.5 Convert Data Into A Universal FormatДокумент12 страниц12.2.1.5 Convert Data Into A Universal FormatАндрій ЗелінськийОценок пока нет
- РГР ВерификацияДокумент18 страницРГР ВерификацияhaleevfОценок пока нет
- © Sap Ag AC410 7-9Документ34 страницы© Sap Ag AC410 7-920215178Оценок пока нет
- Romexis DB BackUp Info - Not Finished v2014-05-16 PDFДокумент22 страницыRomexis DB BackUp Info - Not Finished v2014-05-16 PDFtestОценок пока нет
- Интеграция входящего процесса с упаковкой в ECC (EWM)Документ12 страницИнтеграция входящего процесса с упаковкой в ECC (EWM)HasheckОценок пока нет
- Практика освоения ABAP CDS для непрограммистовДокумент168 страницПрактика освоения ABAP CDS для непрограммистовHasheckОценок пока нет
- Щербаченко ЛР 2Документ17 страницЩербаченко ЛР 2Petr ZubovОценок пока нет
- Справочник Power Pivot - Язык DAX - На РусскомДокумент709 страницСправочник Power Pivot - Язык DAX - На РусскомInga SimpaОценок пока нет
- Manual Asc 3.0 - 2020v10Документ55 страницManual Asc 3.0 - 2020v10Murat CrafterОценок пока нет
- ToyotaДокумент6 страницToyotaZhanar RaibekovaОценок пока нет
- BC670 v46c en 2001 09Документ225 страницBC670 v46c en 2001 09Debopriyo MallickОценок пока нет
- Что делать если сервер 1СПредприятие не обнаруженДокумент5 страницЧто делать если сервер 1СПредприятие не обнаруженЭллада ИваненкоОценок пока нет
- Обновление Базы Данных OracleДокумент2 страницыОбновление Базы Данных Oracledeelan wolczykОценок пока нет
- Лабораторная работа 3 PDFДокумент4 страницыЛабораторная работа 3 PDFmokawar960Оценок пока нет
- МУ - ПЗ 2-4Документ9 страницМУ - ПЗ 2-4Ayazhan TashmuratОценок пока нет
- Инсталляция Администрирование 1СДокумент21 страницаИнсталляция Администрирование 1СEduardОценок пока нет
- 6.1 SQL-инъекцииДокумент27 страниц6.1 SQL-инъекцииsparrowhunetrОценок пока нет
- 4 Безопасность SQL ServerДокумент1 страница4 Безопасность SQL Serverhannes.dzialekОценок пока нет
- SAP Batch Information CockpitДокумент25 страницSAP Batch Information CockpitIgor -Оценок пока нет
- MWD14-007RUSS Advantage Step by Step REV AДокумент52 страницыMWD14-007RUSS Advantage Step by Step REV AAlexey BocharovОценок пока нет
- Отчет курбоновДокумент26 страницОтчет курбоновMuhamad KurbonovОценок пока нет
- Лаб. роб. № 4.1 Проекти з БД. JDBCДокумент4 страницыЛаб. роб. № 4.1 Проекти з БД. JDBCAnonimОценок пока нет
- Шлыков С.В - ЭЭТм - 1705а-51-107Документ57 страницШлыков С.В - ЭЭТм - 1705а-51-107murad5bayramliОценок пока нет
- Использование Scrutor для автоматической регистрации ваших сервисов в контейнере ASP.NET Core DIДокумент15 страницИспользование Scrutor для автоматической регистрации ваших сервисов в контейнере ASP.NET Core DIdmitryОценок пока нет
- Лабораторная работа 2 рус ШППДокумент6 страницЛабораторная работа 2 рус ШППАдилет КамзаОценок пока нет
- Подсистема - Инструменты Разработчика - v2Документ6 страницПодсистема - Инструменты Разработчика - v2Darcicley LopesОценок пока нет
- Подсистема - Инструменты разработчика - v2Документ6 страницПодсистема - Инструменты разработчика - v2Darcicley LopesОценок пока нет
- 02 - Урок 2 Конфигурация СистемыДокумент21 страница02 - Урок 2 Конфигурация СистемыСеймур НоврузовОценок пока нет
- Se e Louco PDFДокумент54 страницыSe e Louco PDFNicollas MeneghelОценок пока нет
- По Дисциплине: "Проектирование Информационных Систем" На Тему: "Проектирование Экономической Информационной Системы По Учету Инвентаризации Материальных Ценностей С Помощью Case-Средств Bpwin"Документ21 страницаПо Дисциплине: "Проектирование Информационных Систем" На Тему: "Проектирование Экономической Информационной Системы По Учету Инвентаризации Материальных Ценностей С Помощью Case-Средств Bpwin"dainoomОценок пока нет
- Ис КинотеатраДокумент24 страницыИс КинотеатраVladimir SelmorОценок пока нет
- Описание - интеграционной модели - v1.1 - 20221213 - правкиДокумент23 страницыОписание - интеграционной модели - v1.1 - 20221213 - правкиVladislav PopovОценок пока нет
- Erp Academy-Muzichenko-Remontnoe ProizvodstvoДокумент16 страницErp Academy-Muzichenko-Remontnoe ProizvodstvoЦЕНТР ПРОФЕССИОНАЛЬНЫХ КОМПЕТЕНЦИЙ ТОИР ProОценок пока нет
- Measurement Studio: практика разработки систем измерения и управления на С#От EverandMeasurement Studio: практика разработки систем измерения и управления на С#Оценок пока нет
- Методы распределения вычислительных ресурсов между пользователями ИСДокумент46 страницМетоды распределения вычислительных ресурсов между пользователями ИСEvgeniyaОценок пока нет
- sidexis 4.4 - ЧастьДокумент75 страницsidexis 4.4 - Частьservice.bmedicalОценок пока нет
- Dorian - Saran C Iuc@ati - Utm.mdДокумент18 страницDorian - Saran C Iuc@ati - Utm.mdAsfefvhhОценок пока нет
- Lab 4 Filimonova ArinaДокумент12 страницLab 4 Filimonova ArinaАрина Филимонова100% (1)












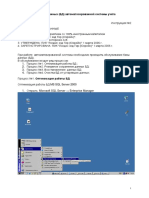






















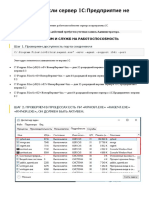





























Скачать как docx, pdf или txt
Вам также может понравиться
- Hibernate Recipes, 2nd EditionДокумент271 страницаHibernate Recipes, 2nd EditionAna ButurajacОценок пока нет
- Практика освоения ABAP CDS для непрограммистов. Часть 1Документ88 страницПрактика освоения ABAP CDS для непрограммистов. Часть 1Rasul11Оценок пока нет
- 10 Лекция - Хранимые процедуры и триггерыДокумент17 страниц10 Лекция - Хранимые процедуры и триггерыmokawar960Оценок пока нет
- НАСТРОЙКА БД Oracle Primavera P6Документ14 страницНАСТРОЙКА БД Oracle Primavera P6Андрей МакаренкоОценок пока нет
- АИС AMOSДокумент10 страницАИС AMOSНатОценок пока нет
- НИРДокумент7 страницНИРsuhorukovdmitryОценок пока нет
- ROWERCENTER INTEGRATSIYA DANNYH DLYA RAZRABOTCHIKOV UROVEN 2 - v25092018Документ6 страницROWERCENTER INTEGRATSIYA DANNYH DLYA RAZRABOTCHIKOV UROVEN 2 - v25092018ПетрОценок пока нет
- Контрольные вопросы по 1С.Документ3 страницыКонтрольные вопросы по 1С.nwytgnetОценок пока нет
- SQL LektsiiRusДокумент48 страницSQL LektsiiRusbegimayОценок пока нет
- Abap Cds. Определение Ракурсов и Профилей в Репозитарии. (s4d430)Документ17 страницAbap Cds. Определение Ракурсов и Профилей в Репозитарии. (s4d430)Сергей З.Оценок пока нет
- МУ по ЛР, БСБДДокумент42 страницыМУ по ЛР, БСБДAlexОценок пока нет
- ПВНСЗД ПЗ № 1Документ39 страницПВНСЗД ПЗ № 1vladyslav.ulanОценок пока нет
- Обслуживание БДДокумент16 страницОбслуживание БДIt's somethingОценок пока нет
- Change NotificationДокумент31 страницаChange NotificationOlga ShОценок пока нет
- PCS P02 83Документ4 страницыPCS P02 83gosiw74599Оценок пока нет
- Администрирование ViPNet (W L) - Практикум 8.12 - 8.13. СОХРАНЕНИЕ НАСТРОЕК. РАСПИСАНИЕДокумент3 страницыАдминистрирование ViPNet (W L) - Практикум 8.12 - 8.13. СОХРАНЕНИЕ НАСТРОЕК. РАСПИСАНИЕKv142 KvОценок пока нет
- ! - Руководство По MySQL - metanit - 81стр - 2018Документ77 страниц! - Руководство По MySQL - metanit - 81стр - 2018OlyaОценок пока нет
- Администрирование базы данныхДокумент28 страницАдминистрирование базы данныхНиколай ДиканскийОценок пока нет
- Документ Microsoft WordДокумент2 страницыДокумент Microsoft WordSergey KomlevОценок пока нет
- Ramus Laba IDEF DFDДокумент18 страницRamus Laba IDEF DFDArseniy RedzhepovОценок пока нет
- Практическая Работа с Механизмами РасширениямиДокумент6 страницПрактическая Работа с Механизмами РасширениямиHelenОценок пока нет
- SQL Advanced - Лекция 2Документ28 страницSQL Advanced - Лекция 2Кристина КабановаОценок пока нет
- IG Content Server 640Документ16 страницIG Content Server 640borinsky1Оценок пока нет
- Доклад по Microsoft AzureДокумент5 страницДоклад по Microsoft AzureVictorОценок пока нет
- 12.2.1.5 Convert Data Into A Universal FormatДокумент12 страниц12.2.1.5 Convert Data Into A Universal FormatАндрій ЗелінськийОценок пока нет
- РГР ВерификацияДокумент18 страницРГР ВерификацияhaleevfОценок пока нет
- © Sap Ag AC410 7-9Документ34 страницы© Sap Ag AC410 7-920215178Оценок пока нет
- Romexis DB BackUp Info - Not Finished v2014-05-16 PDFДокумент22 страницыRomexis DB BackUp Info - Not Finished v2014-05-16 PDFtestОценок пока нет
- Интеграция входящего процесса с упаковкой в ECC (EWM)Документ12 страницИнтеграция входящего процесса с упаковкой в ECC (EWM)HasheckОценок пока нет
- Практика освоения ABAP CDS для непрограммистовДокумент168 страницПрактика освоения ABAP CDS для непрограммистовHasheckОценок пока нет
- Щербаченко ЛР 2Документ17 страницЩербаченко ЛР 2Petr ZubovОценок пока нет
- Справочник Power Pivot - Язык DAX - На РусскомДокумент709 страницСправочник Power Pivot - Язык DAX - На РусскомInga SimpaОценок пока нет
- Manual Asc 3.0 - 2020v10Документ55 страницManual Asc 3.0 - 2020v10Murat CrafterОценок пока нет
- ToyotaДокумент6 страницToyotaZhanar RaibekovaОценок пока нет
- BC670 v46c en 2001 09Документ225 страницBC670 v46c en 2001 09Debopriyo MallickОценок пока нет
- Что делать если сервер 1СПредприятие не обнаруженДокумент5 страницЧто делать если сервер 1СПредприятие не обнаруженЭллада ИваненкоОценок пока нет
- Обновление Базы Данных OracleДокумент2 страницыОбновление Базы Данных Oracledeelan wolczykОценок пока нет
- Лабораторная работа 3 PDFДокумент4 страницыЛабораторная работа 3 PDFmokawar960Оценок пока нет
- МУ - ПЗ 2-4Документ9 страницМУ - ПЗ 2-4Ayazhan TashmuratОценок пока нет
- Инсталляция Администрирование 1СДокумент21 страницаИнсталляция Администрирование 1СEduardОценок пока нет
- 6.1 SQL-инъекцииДокумент27 страниц6.1 SQL-инъекцииsparrowhunetrОценок пока нет
- 4 Безопасность SQL ServerДокумент1 страница4 Безопасность SQL Serverhannes.dzialekОценок пока нет
- SAP Batch Information CockpitДокумент25 страницSAP Batch Information CockpitIgor -Оценок пока нет
- MWD14-007RUSS Advantage Step by Step REV AДокумент52 страницыMWD14-007RUSS Advantage Step by Step REV AAlexey BocharovОценок пока нет
- Отчет курбоновДокумент26 страницОтчет курбоновMuhamad KurbonovОценок пока нет
- Лаб. роб. № 4.1 Проекти з БД. JDBCДокумент4 страницыЛаб. роб. № 4.1 Проекти з БД. JDBCAnonimОценок пока нет
- Шлыков С.В - ЭЭТм - 1705а-51-107Документ57 страницШлыков С.В - ЭЭТм - 1705а-51-107murad5bayramliОценок пока нет
- Использование Scrutor для автоматической регистрации ваших сервисов в контейнере ASP.NET Core DIДокумент15 страницИспользование Scrutor для автоматической регистрации ваших сервисов в контейнере ASP.NET Core DIdmitryОценок пока нет
- Лабораторная работа 2 рус ШППДокумент6 страницЛабораторная работа 2 рус ШППАдилет КамзаОценок пока нет
- Подсистема - Инструменты Разработчика - v2Документ6 страницПодсистема - Инструменты Разработчика - v2Darcicley LopesОценок пока нет
- Подсистема - Инструменты разработчика - v2Документ6 страницПодсистема - Инструменты разработчика - v2Darcicley LopesОценок пока нет
- 02 - Урок 2 Конфигурация СистемыДокумент21 страница02 - Урок 2 Конфигурация СистемыСеймур НоврузовОценок пока нет
- Se e Louco PDFДокумент54 страницыSe e Louco PDFNicollas MeneghelОценок пока нет
- По Дисциплине: "Проектирование Информационных Систем" На Тему: "Проектирование Экономической Информационной Системы По Учету Инвентаризации Материальных Ценностей С Помощью Case-Средств Bpwin"Документ21 страницаПо Дисциплине: "Проектирование Информационных Систем" На Тему: "Проектирование Экономической Информационной Системы По Учету Инвентаризации Материальных Ценностей С Помощью Case-Средств Bpwin"dainoomОценок пока нет
- Ис КинотеатраДокумент24 страницыИс КинотеатраVladimir SelmorОценок пока нет
- Описание - интеграционной модели - v1.1 - 20221213 - правкиДокумент23 страницыОписание - интеграционной модели - v1.1 - 20221213 - правкиVladislav PopovОценок пока нет
- Erp Academy-Muzichenko-Remontnoe ProizvodstvoДокумент16 страницErp Academy-Muzichenko-Remontnoe ProizvodstvoЦЕНТР ПРОФЕССИОНАЛЬНЫХ КОМПЕТЕНЦИЙ ТОИР ProОценок пока нет
- Measurement Studio: практика разработки систем измерения и управления на С#От EverandMeasurement Studio: практика разработки систем измерения и управления на С#Оценок пока нет
- Методы распределения вычислительных ресурсов между пользователями ИСДокумент46 страницМетоды распределения вычислительных ресурсов между пользователями ИСEvgeniyaОценок пока нет
- sidexis 4.4 - ЧастьДокумент75 страницsidexis 4.4 - Частьservice.bmedicalОценок пока нет
- Dorian - Saran C Iuc@ati - Utm.mdДокумент18 страницDorian - Saran C Iuc@ati - Utm.mdAsfefvhhОценок пока нет
- Lab 4 Filimonova ArinaДокумент12 страницLab 4 Filimonova ArinaАрина Филимонова100% (1)