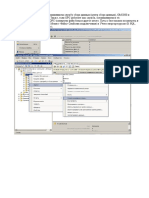
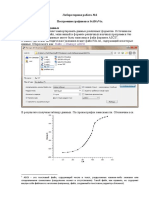
Вам также может понравиться
- Работа с BigData в облаках. Обработка и хранение данных с примерами из Microsoft AzureОт EverandРабота с BigData в облаках. Обработка и хранение данных с примерами из Microsoft AzureОценок пока нет
- LR 6Документ5 страницLR 6Italmas PavelОценок пока нет
- Measurement Studio: практика разработки систем измерения и управления на С#От EverandMeasurement Studio: практика разработки систем измерения и управления на С#Оценок пока нет
- Лаб1Документ12 страницЛаб1АлексейОценок пока нет
- Fa 59 F 7 C 08 FДокумент3 страницыFa 59 F 7 C 08 FВлад СолуяновОценок пока нет
- Лекция 2 (OLAP куб)Документ9 страницЛекция 2 (OLAP куб)kirilldolgopolov527Оценок пока нет
- ГТД. Термогазодинамические расчетыДокумент10 страницГТД. Термогазодинамические расчетыПетрОценок пока нет
- 2 русДокумент6 страниц2 русРауан ЖаксылыковОценок пока нет
- Лекция 6 - Выявление параллелизма алгоритмовДокумент9 страницЛекция 6 - Выявление параллелизма алгоритмовTerry CrewsОценок пока нет
- Programarea C++Документ86 страницProgramarea C++rgrgrgrgrgrrg0% (1)
- Лабораторная работа 6Документ5 страницЛабораторная работа 6Denis DoroshkoОценок пока нет
- ИТ методичкаДокумент83 страницыИТ методичкаlailainformОценок пока нет
- Лаб БД Delphi 16Документ16 страницЛаб БД Delphi 16Сергей ШпаковскийОценок пока нет
- Лабораторная работа №2 - часть 1Документ17 страницЛабораторная работа №2 - часть 1Сабрина КухареваОценок пока нет
- C LabДокумент48 страницC LabKlaus MuellerОценок пока нет
- Щербаченко ЛР 2Документ17 страницЩербаченко ЛР 2Petr ZubovОценок пока нет
- UntitledДокумент11 страницUntitledЭльдар НургалиевОценок пока нет
- Lab 2 AMOO UTMДокумент6 страницLab 2 AMOO UTMIgorОценок пока нет
- Лаб БД Delphi 22 TreeView PDFДокумент15 страницЛаб БД Delphi 22 TreeView PDFСергей ШпаковскийОценок пока нет
- КУРСАВАЯ ИСМАТДокумент18 страницКУРСАВАЯ ИСМАТJannat IsmoilОценок пока нет
- база данных лаб1Документ12 страницбаза данных лаб1jovid.jamshed90Оценок пока нет
- Методичка ИнформатикаДокумент28 страницМетодичка ИнформатикаNeymar JrОценок пока нет
- MS Excelda Ststik FunksiyalarДокумент9 страницMS Excelda Ststik FunksiyalarOg'abek MadrimovОценок пока нет
- MS Excelda Ststik FunksiyalarДокумент9 страницMS Excelda Ststik FunksiyalarOg'abek MadrimovОценок пока нет
- Protocol Mvt2mДокумент30 страницProtocol Mvt2mВиталий ПилыкОценок пока нет
- ОСНОВНЫЕ ПОНЯТИЯ БАЗЫ ДАННЫХ 1 ЗАНЯТИЕДокумент5 страницОСНОВНЫЕ ПОНЯТИЯ БАЗЫ ДАННЫХ 1 ЗАНЯТИЕасланОценок пока нет
- Progr Ingeneria WebДокумент130 страницProgr Ingeneria WebastryapkoОценок пока нет
- Metod IadДокумент50 страницMetod IadNagОценок пока нет
- Youssef 32Документ13 страницYoussef 32ahmed m abdelkawyОценок пока нет
- ТехнологияДокумент35 страницТехнологияАлексей ДикунОценок пока нет
- 1Документ26 страниц1igorОценок пока нет
- IQ ботДокумент14 страницIQ ботSqrMalevichaОценок пока нет
- ЛАБОРАТОРНАЯ РАБОТА №1 - Структура - механизм абстракцииДокумент11 страницЛАБОРАТОРНАЯ РАБОТА №1 - Структура - механизм абстракцииAlex DerОценок пока нет
- Lab 5Документ28 страницLab 5FaiterОценок пока нет
- Команды DMLДокумент6 страницКоманды DMLkalbaevtОценок пока нет
- Интеллектуальный анализ данныхДокумент51 страницаИнтеллектуальный анализ данныхMaria DemidikОценок пока нет
- Урок 15Документ24 страницыУрок 15Ілона ГригоракОценок пока нет
- Лаб БД Delphi 24 - Работа с сеткой DBGridДокумент12 страницЛаб БД Delphi 24 - Работа с сеткой DBGridСергей ШпаковскийОценок пока нет
- Abap 21432325 210224 2243 1116Документ7 страницAbap 21432325 210224 2243 1116Вадим ЛапыгинОценок пока нет
- Microsoft AccessДокумент34 страницыMicrosoft AccessWGDWGDОценок пока нет
- Лабораторная работа 10-18 MATLABДокумент52 страницыЛабораторная работа 10-18 MATLABЕвгений ЮдинОценок пока нет
- Формирование МакетовДокумент8 страницФормирование МакетовIt's somethingОценок пока нет
- Инструкция по добавлению нового счетчикаДокумент10 страницИнструкция по добавлению нового счетчикаshingysОценок пока нет
- Iu7 Cprog Sem 2 Lab 10Документ18 страницIu7 Cprog Sem 2 Lab 10akjllkajsОценок пока нет
- Лаб БД Delphi 23 Quick ReportДокумент12 страницЛаб БД Delphi 23 Quick ReportСергей ШпаковскийОценок пока нет
- ЛР№1 12Документ8 страницЛР№1 12DEN INSIDEОценок пока нет
- Инструкция по АСКУЭДокумент20 страницИнструкция по АСКУЭshingysОценок пока нет
- КоганЯС 6307 отчет НИР бакалавра 6семестр 2022Документ26 страницКоганЯС 6307 отчет НИР бакалавра 6семестр 2022Jacob KoganОценок пока нет
- Лекц 7 Диаграммы Use CaseДокумент34 страницыЛекц 7 Диаграммы Use CaseJ.J. JacksonОценок пока нет
- 2023 08 14 Лабораторная Работа 1 Изучение Ввода Вывода ДинамическоеДокумент7 страниц2023 08 14 Лабораторная Работа 1 Изучение Ввода Вывода Динамическоеdhghbyx8hdОценок пока нет
- © УГТУ-УПИ,2013Документ88 страниц© УГТУ-УПИ,2013VladОценок пока нет
- Практика По Администрированию Oracle 11g I 2017 (Блок 3 Лабораторные 10-13)Документ14 страницПрактика По Администрированию Oracle 11g I 2017 (Блок 3 Лабораторные 10-13)apis88Оценок пока нет
- § 2. Работа с таблицами базы данныхДокумент1 страница§ 2. Работа с таблицами базы данныхreradailyОценок пока нет
- АС7Документ15 страницАС7Сенат Парламента Республики КазахстанОценок пока нет
- NT Oj NHT, FДокумент9 страницNT Oj NHT, Fgorbachgalina99Оценок пока нет
- SciDAVis 2Документ6 страницSciDAVis 2Randy YananeniОценок пока нет
- Ð Ñ Ñ Ñ Ð Ð Ð°Ñ Ð¡Ñ Ð Ð¿Ð ÐДокумент22 страницыÐ Ñ Ñ Ñ Ð Ð Ð°Ñ Ð¡Ñ Ð Ð¿Ð Ðzws2vmbks7Оценок пока нет
- Анализ Данных В Среде MatlabДокумент272 страницыАнализ Данных В Среде Matlabnauhm6838Оценок пока нет
- Лабораторная работа 10 (п) - Часть2Документ9 страницЛабораторная работа 10 (п) - Часть2Daniil, -Give me the loot?Оценок пока нет
- Movement of The Planets The Calculation and Visualization in Mathcad or Keplers Watch PDFДокумент39 страницMovement of The Planets The Calculation and Visualization in Mathcad or Keplers Watch PDFKОценок пока нет
- Справочник По Языку cДокумент403 страницыСправочник По Языку cАндрей ПетуховОценок пока нет
- Elasticsearch, Kibana, Logstash и поисковые системы нового поколенияДокумент518 страницElasticsearch, Kibana, Logstash и поисковые системы нового поколенияJonathan Seagull LivingstonОценок пока нет
- Заказы на собственные затраты ControllingДокумент186 страницЗаказы на собственные затраты ControllingArtem BoitsovОценок пока нет
- ConvertXtoDVD 3 Russian ManualДокумент46 страницConvertXtoDVD 3 Russian ManualRobert ThomasОценок пока нет
- CadMaster2005 05Документ108 страницCadMaster2005 05stelikcОценок пока нет
- 40 алгоритмов, которые должен знать каждый программист на PythonОт Everand40 алгоритмов, которые должен знать каждый программист на PythonОценок пока нет
- Система моделирования и исследования радиоэлектронных устройств Multisim 10От EverandСистема моделирования и исследования радиоэлектронных устройств Multisim 10Оценок пока нет
- Социальные медиа маркетинг для малого бизнеса: Как привлечь новых клиентов, заработать больше денег и выделиться из толпыОт EverandСоциальные медиа маркетинг для малого бизнеса: Как привлечь новых клиентов, заработать больше денег и выделиться из толпыОценок пока нет
- Блокчейн: архитектура, криптовалюты, инструменты разработки, смарт-контрактыОт EverandБлокчейн: архитектура, криптовалюты, инструменты разработки, смарт-контрактыОценок пока нет
- Unity в действии. Мультиплатформенная разработка на C#. 2-е межд. изданиеОт EverandUnity в действии. Мультиплатформенная разработка на C#. 2-е межд. изданиеОценок пока нет
- Заставьте данные говорить: Как сделать бизнес-дашборд в Excel. Руководство по визуализации данныхОт EverandЗаставьте данные говорить: Как сделать бизнес-дашборд в Excel. Руководство по визуализации данныхОценок пока нет
- Простой подход к фундаментальному инвестиционному анализу: Вводное руководство по методам фундаментального анализа и стратегиям предвидения событий, которые движут рынкамиОт EverandПростой подход к фундаментальному инвестиционному анализу: Вводное руководство по методам фундаментального анализа и стратегиям предвидения событий, которые движут рынкамиОценок пока нет
- Руководство по рекламе Google: Вводный путеводитель по самой известной и популярной рекламной программе в сети: основная информация и ключевые моменты, которые необходимо знатьОт EverandРуководство по рекламе Google: Вводный путеводитель по самой известной и популярной рекламной программе в сети: основная информация и ключевые моменты, которые необходимо знатьОценок пока нет
- Как вернуть клиента на сайт: ретаргетинг, ремаркетинг, email и не толькоОт EverandКак вернуть клиента на сайт: ретаргетинг, ремаркетинг, email и не толькоОценок пока нет
- Простой подход к торговле на рынке форекс: Вводное руководство по рынку Форекс и наиболее эффективным стратегиям торговли валютойОт EverandПростой подход к торговле на рынке форекс: Вводное руководство по рынку Форекс и наиболее эффективным стратегиям торговли валютойОценок пока нет
- Простой подход к техническому анализу инвестиций: Как построить и интерпретировать графики технического анализа, чтобы улучшить вашу активность в онлайн-торговлеОт EverandПростой подход к техническому анализу инвестиций: Как построить и интерпретировать графики технического анализа, чтобы улучшить вашу активность в онлайн-торговлеОценок пока нет
- Простой подход к интернет-трейдингу: Как научиться основам интернет-трейдинга для успешной торговли на финансовых рынкахОт EverandПростой подход к интернет-трейдингу: Как научиться основам интернет-трейдинга для успешной торговли на финансовых рынкахОценок пока нет
- Старший брат следит за тобой: Как защитить себя в цифровом миреОт EverandСтарший брат следит за тобой: Как защитить себя в цифровом миреОценок пока нет
- Искусственный интеллект отвечает на величайшие вопросы человечества. Что делает нас людьми?От EverandИскусственный интеллект отвечает на величайшие вопросы человечества. Что делает нас людьми?Оценок пока нет